2024. 11. 26. 18:35ㆍPower BI/파워 쿼리 ( Power Qeury )
파워쿼리를 이용한 PDF에서 데이터를 가져오는 것을 알아보도록 하겠습니다.
가끔 데이터를 엑셀, csv 파일이 아닌 PDF 파일로 주는 경우가 있습니다.
이때 사용할 수 있는 방법입니다.
아래와 같이 일자별 데이터가 pdf파일 형식의 데이터가 있습니다.
요즘에는 다양하게 PDF를 추출하는 방법들이 있어서 해당 항목을 데이터로 전환할 수 있겠지만
테이블 형식이기 때문에 파워쿼리를 이용한 추출을 진행해 보도록 하겠습니다.

[ 데이터 ] - [ 파일에서 ] - [ PDF에서 ]를 클릭 해 보도록 하겠습니다.
파일에서의 옵션 중에서
Excel, CSV, 폴더에서, SharePoint 폴더에서, 그리고 PDF 파일
순서로 사용 빈도가 있을 거 같습니다.
자주 사용하지 않지만 알아두면 매우 유용할 것이라고 생각합니다.
탐색 창을 살펴보도록 하겠습니다.
Table001(Page 1), Table002 (Page 2), Page001, Page002의 4가지 항목이 나오는 것을 볼 수 있습니다.
Excel이었으면 아마 Sheet 명이 생성이 되었을 것입니다.
Table은 엑셀에서의 표
Page001은 엑셀에서 Sheet라고 생각하시면 좋을 것 같습니다.
저는 Table을 가지고 작업을 해 보도록 하겠습니다.
[ 데이터 변환 ]을 눌러서 파워쿼리 편집기로 해당 데이터를 불러오도록 하겠습니다.
분명히 11월 1, 2일 실적이 나와야 하는데 하나만 나오는 것을 볼 수 있습니다.

엑셀에서와 마찬가지로 Sheet를 합친다는 생각으로 원본으로 이동해 보도록 하겠습니다.
[ 파워쿼리 ] 엑셀 시트 데이터 합치기
엑셀의 한계를 극복하기 위한 방법을 알아보도록 하겠습니다.다음과 같이 데이터를 준비해 보도록 하겠습니다.11/1일11/2일합계 : 529,419,156합계 : 529,635,427 이전에 이야기를 드린 것과 같이 엑셀
sunconnector.tistory.com
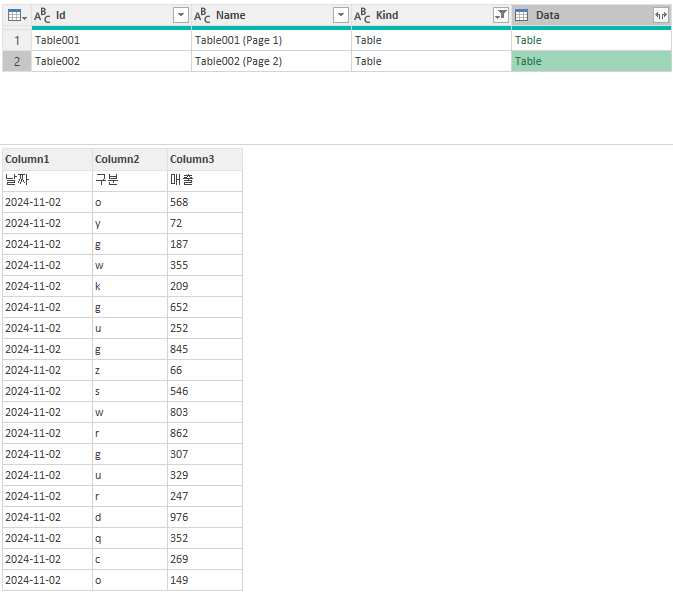
Kind가 Table 형식과 Page 형식이 있는데 Table 형식으로 작업을 하려고 하였으니
Kind를 Table로 필터를 진행해 보도록 하겠습니다.

아래와 같이 Table 형식만 남는 것을 볼 수 있습니다.

1, 2일의 값이 각각의 테이블에 들어와 있는 것을 볼 수 있습니다.
※ Page를 선택해도 같은 결과를 얻으실 수 있습니다.
두 개의 차이점이 있지만 여기서는 언급하지 않고 넘어가겠습니다.
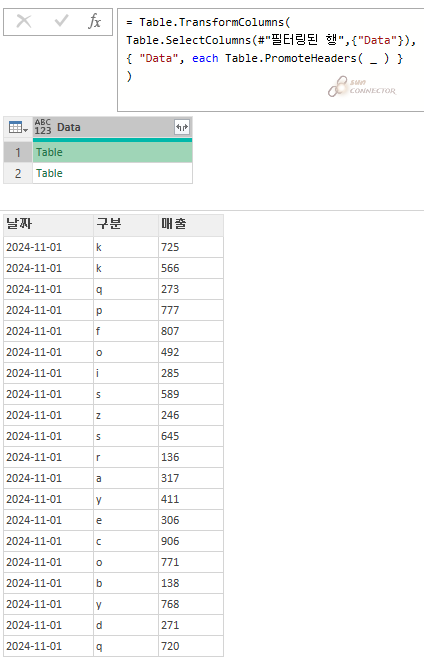
제 앞의 글을 보면 제가 가장 좋아하는 함수인
Table.TransformColumns를 사용하면 첫 행을 머리글로 올려서 작업할 수 있기 때문에
확장하기 전에 머리글을 올려 줍니다.
아래와 같이 수식을 입력해 주니 아까와는 다르게 첫 행을 모두 헤더로 사용하는 것을 볼 수 있습니다.
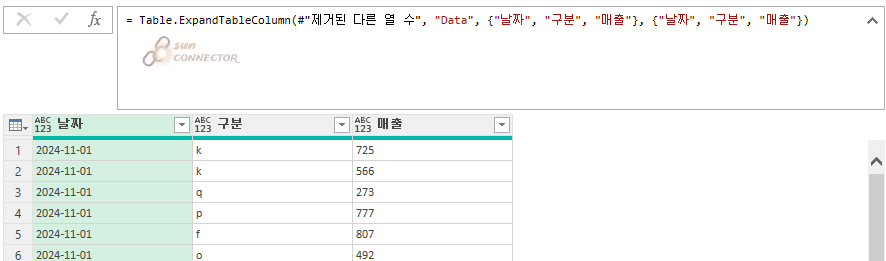
아래와 같이 확장을 해 주도록 하겠습니다.
그리고 닫기 및 로드를 눌러서 표로 출력해 보도록 하겠습니다.
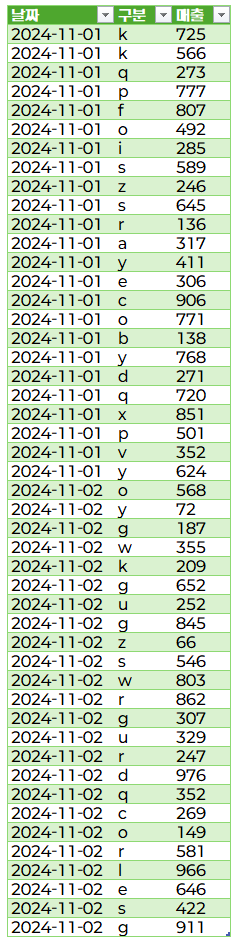
아래와 같이 PDF에서 데이를 가져온 것을 확인할 수 있습니다.
VS. 헤더를 올리지 않고 작업을 하면 불편한 점은 무엇일까요? 다시 헤더를 사용하지 않은 상황으로 돌아가 보도록 하겠습니다. 이 상태에서 바로 확장을 해 보도록 하겠습니다.  컬럼명이 아닌 Column 형식의 이름이 생성되어 있습니다. 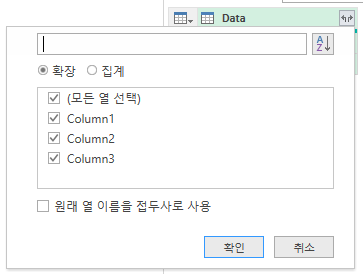 확장 후 첫행을 머리글로 사용을 눌러 주도록 하겠습니다. 그리고 닫기 및 로드를 눌러 보도록 하겠습니다.  아래와 같은 결과가 나옵니다. 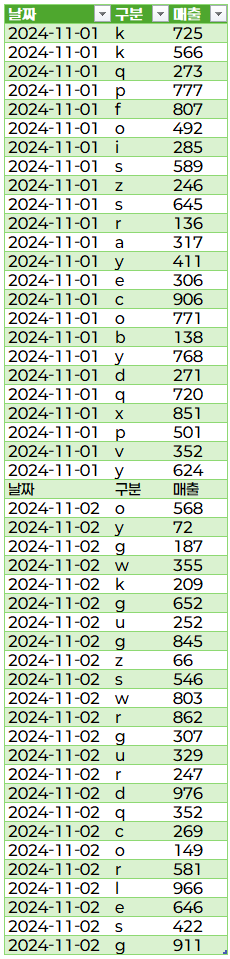 중간에 불필요한 항목이 있는 것이 보이십니까? 필터링을 마지막에 한번 더 해줘야 하는 불편함을 줄 일 수 있습니다. 그리고 가장 중요한 것을 추후에 빅데이터를 관리할 때 해당 항목으로 인한 결과가 제대로 나오지 않아 원인을 찾을 때 상당한 시간이 소요될 수 있습니다. |

'Power BI > 파워 쿼리 ( Power Qeury )' 카테고리의 다른 글
| [ 파워쿼리 ] 데이터 정규화 (0) | 2024.12.04 |
|---|---|
| [ 파워쿼리 ] 청계천 박물관 입장객수 (0) | 2024.11.27 |
| [ 파워쿼리 ] 테이블 컬럼 한번에 변경하기 (0) | 2024.11.25 |
| [ 파워쿼리 ] null 값 바꾸기 ( 결측값 처리 ) (0) | 2024.11.24 |
| [ 파워쿼리 ] if, 다중 if ( 조건열 ) 사용하기 (0) | 2024.11.23 |