2024. 11. 13. 19:11ㆍPower BI/파워 쿼리 ( Power Qeury )
파워쿼리를 사용해서 데이터를 그룹화하는 방법을 알아보도록 하겠습니다.
데이터를 불러와 보도록 하겠습니다.
데이터를 불러오는 방법은 아래글을 참고해 주십시오.
[ 파워쿼리 ] 데이터 불러오기( with. Excel )
파워쿼리의 시작인 데이터 불러오기를 해 보도록 하겠습니다.아래와 같이 엑셀 데이터를 준비해 준 후 바탕화면에 저장해 주었습니다.원본은 건드리지 않는 것이 가장 좋기 때문에새로운 엑셀
sunconnector.tistory.com
아래와 같이 데이터를 준비해 주었습니다.
구분의 값을 기준으로 다양한 집계를 해보도록 하겠습니다.
우선 구분을 내림차순으로 정렬해 보도록 하겠습니다.
우측과 같이 구분값 기준으로 하나의 값이 아닌 다양한 값을 가지고 있는 것을 볼 수 있습니다.

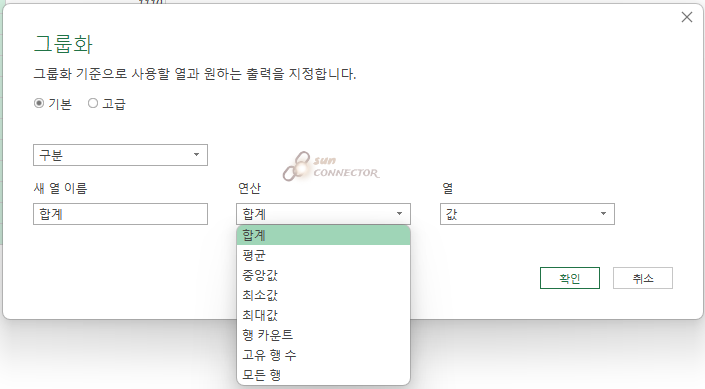
우선 가장 기본이 되는 합계를 구해 보도록 하겠습니다.
[ 홈 ] - [ 그룹화 ]를 눌러 주거나 구분 우클릭으로 그룹화를 선택해 주셔도 됩니다.
그룹화 옵션 창이 나오면 다음과 같이 입력을 해 보도록 하겠습니다.
| 구분 | 새 열 이름 | 연산 | 열 |
| Group 컬럼명 | 합계 | 합계 ( sum ) | 값 |
| 해당 컬럼을 기준으로 | 합계라는 이름의 컬럼으로 | 합계를 구하겠습니다. | 값컬럼의 값들의 |
확인을 누르면 아래와 같이 변하는 것을 확인 할 수 있습니다.
아까 입력한 것을 기준으로 값컬럼의 합계를 "합계"라는 컬럼명으로 변경이 된 것을 볼 수 있습니다.
검증을 해보기 위해서 p를 필터링 후 합계를 한번 해 보도록 하겠습니다.
그리고 계산기로 값을 한번 더해 봅니다. 2,014라는 값이 나옵니다.
아니면 값 컬럼을 선택해 준 후 [ 변환 ] - [ 통계 ] - [ 합계 ]를 눌러 주도록 하겠습니다.
그럼 계산기로 계산한 것과 동일한 결과가 나오는 것을 볼 수 있습니다.
이와 같은 작업을 반복해서 위와 같은 그룹화된 값을 얻을 수 있습니다.
| 그런데 이거 어디서 많이 보신거 아닌가요? 바로 피벗테이블을 사용하면 할 수 있는 동일한 작업입니다 |
이번에는 다양한 옵션에 대해서 알아보도록 하겠습니다.
| 연산 | 결과 | 세부내용 |
| 평균 |  |
p값을 다시 계산기로 계산하면 해당 값이 나오는 것을 볼 수 있습니다. ( 컬럼명도 평균으로 변경 했습니다 ) |
| 중앙값 |  |
p 값을 기준으로 값이 4개일 때 Max, Min 값 제외 후 두개의 값의 평균값 입니다. 값이 2개면 2개의 값의 평균입니다. |
| 최소값 |  |
p값을 기준으로 최소값은 286 입니다 |
| 최대값 |  |
p 값을 기준으로 최대값은 793 입니다 |
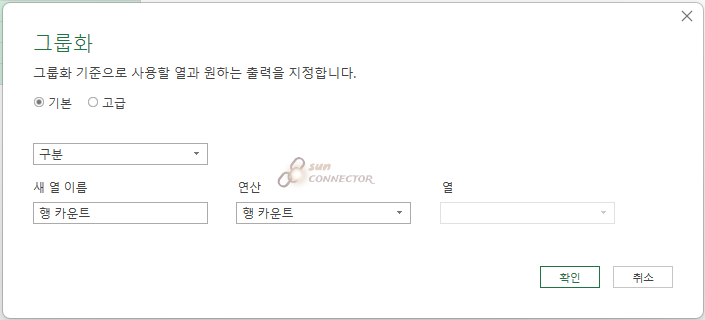
이 번에는 집계가 아닌 행의 개수를 세어 주는 방법입니다.
각 집계 그룹별 열의 숫자를 나타내 줄 수 있는 방법입니다.
집계함수와는 다르게 이번에는 열이 활성화되지 않는 것을 볼 수 있습니다.
비교를 해 주기 위해서 우측와 잠시 원본 데이터를 넣어 주도록 하겠습니다.
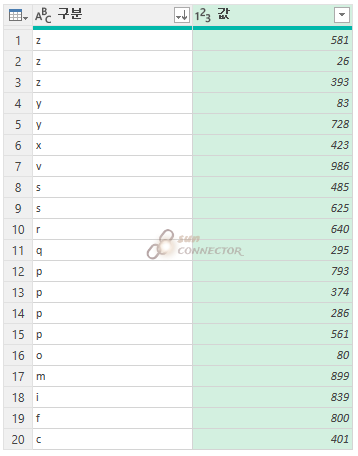
p 값을 기준으로 우측에 보시면 4개의 열이 있는 것을 볼 수 있습니다.
그럼 아래의 s도 같은 결과인지 살펴봅니다.
그럼 행 카운트의 합계는 20이 되어야 모든 데이터를 반영한다고 볼 수 있을 것 같아
검증을 위한 행 카운트 합계를 보도록 하겠습니다.
( 처음에는 계산기로 하는 게 빠르고 제일 좋습니다 )
아래와 같이 모든 행이 반영이 되어 있는 것을 볼 수 있습니다.


그럼 고유 행 수는 행 카운트와 어떻게 다를까요?
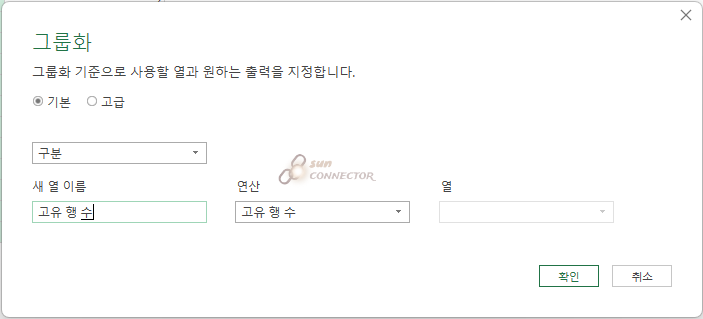
고유 행 수를 알기 위해서 행 카운트 컬럼을 변경하는 것이 아닌 두 개의 컬럼을 다시 그룹 하는 작업을 해 보겠습니다.
이번에는 옵션이 아까와 다르게 고급으로 변경되면서 그룹화하는 행이 2개가 나오는 것을 볼 수 있습니다.
그리고 아래쪽에는 집계 추가의 옵션도 있습니다.
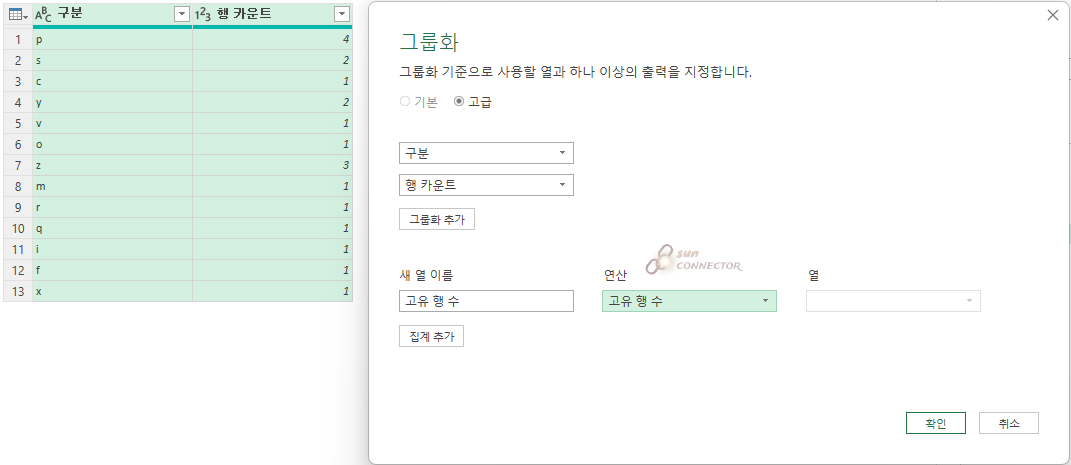
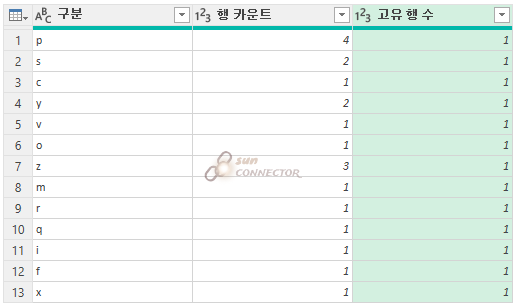
아래와 같은 결과가 나왔습니다.
고유 행 수는 아까와는 다르게 모든 열을 세는 것이 아닌 구분의 고유한 값을 1로 보고 카운트를 하는 방법입니다.
( 간단하게 고유값을 센다고 보시면 됩니다 )
그래서 고유 행 수는 모두 1의 결과값이 나오게 됩니다.
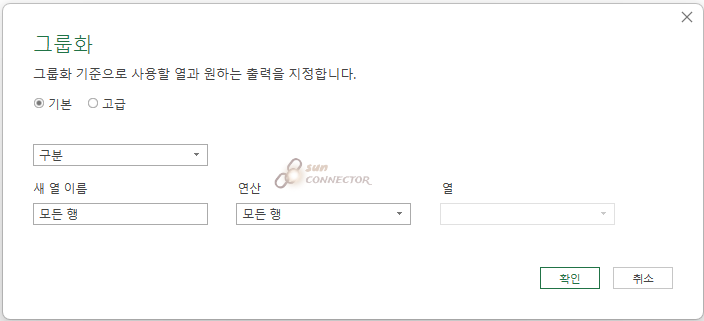
그리고 제가 제일 좋아하는 모든 행 연산입니다.
저는 데이터 전처리를 하면서 모르는 상황이 발생하면 보통 그룹화를 하여 모든 행으로 변환을 해 버립니다.
뭔가 어지러운 상황이 정리되면서 다시 시작하는 느낌이 들어서 좋습니다.
하지만 이 연산은 고급 M function과 같이 써야 효과가 좋아 고급 스킬이라고 할 수 있습니다.
우측을 보시면 아까와는 다르게 결과를 반환하는 것이 아닌 행 안에 다시 Table이 들어 있는 것을 볼 수 있습니다.
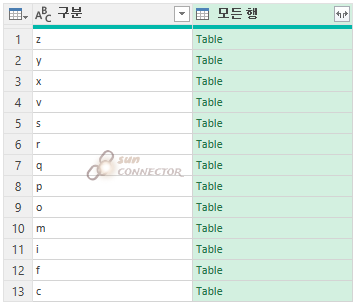
p 값을 한번 눌러보니 아래와 같이 아까 보던 테이블이 들어가 있는 것을 볼 수 있습니다.
이렇게 변환하는 장점이 무엇일까요?
바로 내가 원하는 작업을 한 후에 확장을 해서 데이터 변환이 가능하다는 것입니다.
아래 수식에 있는 each _ 대신에 each [ 값 ]으로 변환해 보도록 하겠습니다.
( 안쪽 테이블의 값 컬럼만 선택하겠다는 의미 )
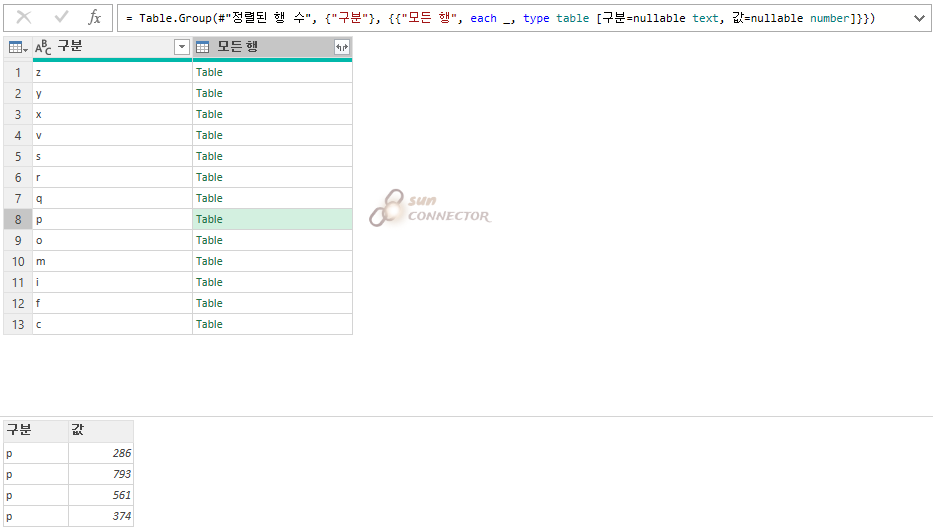
위의 테이블이 아닌 List로 변경이 된 것을 알 수 있습니다.
python으로 생각하면 값을 list 형식으로 가지고 있다가 내가 원하는 값을 출력할 수 있는 상황이라고 생각하시면 됩니다.
그럼 이 상황에서 합계를 한번 구해 보도록 하겠습니다.
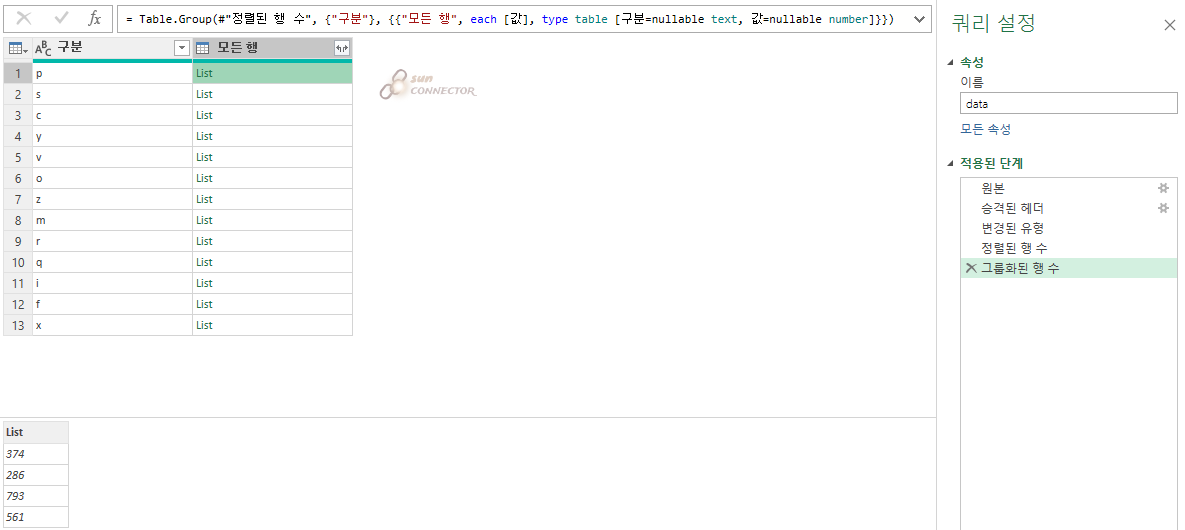
M function의 List함수인 List.Sum을 입력하자 아까 집계 합수에서 사용한 Sum이 되는 것을 볼 수 있습니다.
( 아까 검증할 때 합계를 구하는 방법과 동일한데 이 절차가 열 안에서 작동하는 것입니다 )
그럼 새로운 방법으로 평균을 구해 보도록 하겠습니다.
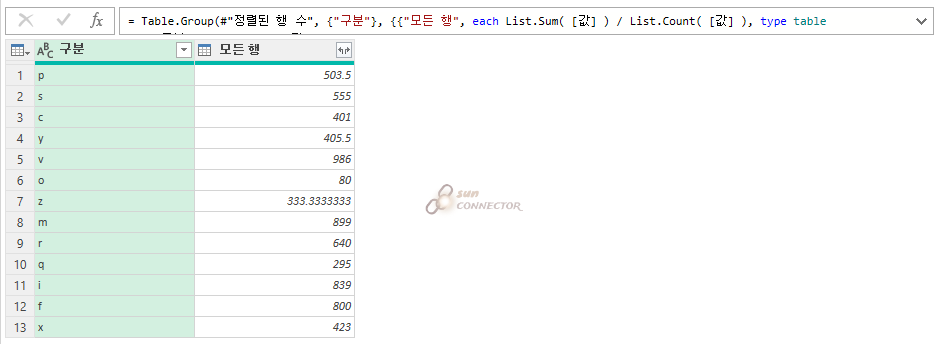
평균 = 합계 / 행 카운드
수식을 활용해서 구해 보도록 하겠습니다.
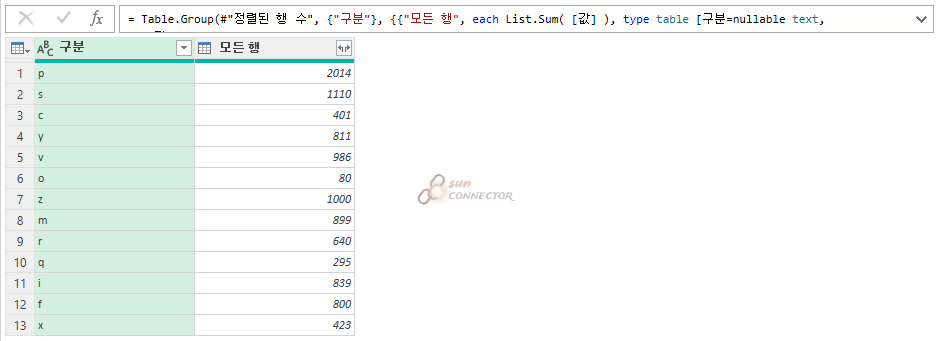
이번에는 List.Count 함수를 사용해서 행 카운트를 빠르게 구해 줍니다.
이제 아까 합계를 행 카운트와 빠르게 나눠 주도록 하겠습니다.
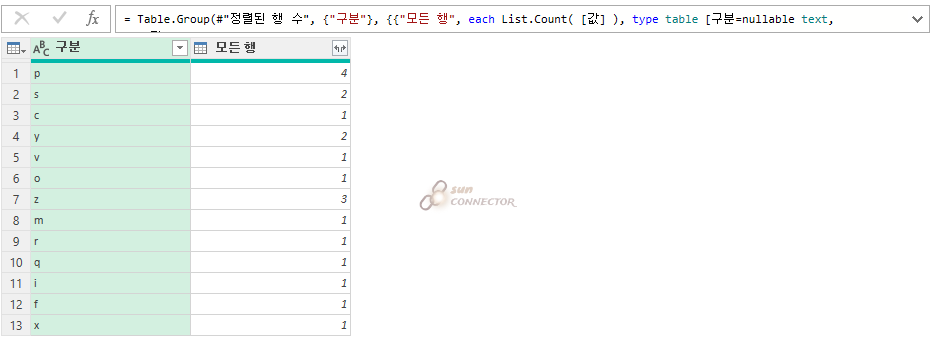
아까와 같은 평균이 구해지는 것을 볼 수 있습니다.
왜 모든 행을 사용해야 할까요? 실제로 활용도가 높을까요? 이 방법을 사용하는 이유는 나만의 함수를 만들 수 있습니다. 실제 데이터를 사용하다보면 기존 함수가 아닌 새로운 방법의 연산이 필요한 경우가 있는데 이런 경우 적용 단계를 많이 적용하지 않고 바로 데이터 처리가 가능합니다. |

'Power BI > 파워 쿼리 ( Power Qeury )' 카테고리의 다른 글
| [ 파워쿼리 ] 텍스트 서식 변경 (0) | 2024.11.15 |
|---|---|
| [ 파워쿼리 ] 날짜 테이블 만들기 (0) | 2024.11.14 |
| [ 파쿼쿼리 ] 다양한 방법으로 열 분할 하기 ( 텍스트 분리하기 ) (0) | 2024.11.12 |
| [ 파워쿼리 ] 엑셀 테이블의 짝수( 홀수 )행만 구하기 (0) | 2024.11.11 |
| [ 파워쿼리 ] 엑셀 열 번호 ( Row number ) 추가 (0) | 2024.11.10 |